
CDISC中Dataset-JSON v1.1标准总结笔记
本文以CDISC官网的Dataset-JSON v1.1标准为主要学习资料,探索以下几个问题:
什么是JSON数据格式;
SDTM数据集的JSON格式长什么样,如何呈现;
dm.json数据集在SAS/R/Python中如何读取和输出;
Dataset-JSON v1.1标准中user guide提到的其他细节;
API v1.0 Standard简要理解。
JSON数据极简介绍
JSON是一种轻量级文本数据交换格式,也是JavaScript中的对象表示法,能够独立于语言为许多编程语言所使用。
语法结构
JSON可以由对象、数组、键值对构成,对象由{}保存,数组由[]保存,键值对(名称/值对)指的是"name":"value",数据间用,分隔,转义字符是\。对象和数组可以无限嵌套,类似树形结构,不管如何嵌套、分多少层,最终只需要落实到键值对即可。
值的类型
可以是数字(整数或浮点数),字符串,逻辑值,数组,对象和null。
数据举例
JSON对象/数组相互嵌套
JSON对象包含在{}中,既可以包含单个/多个键值对,也可以包含数组,互相嵌套的层级是JSON数据格式的特点。
// 单个
{"name" : "Allen"}
// 多个
{
"name" : "Allen",
"Gender" : "Male",
"Appearance" : "Handsome"
}
// 数组、对象相互嵌套
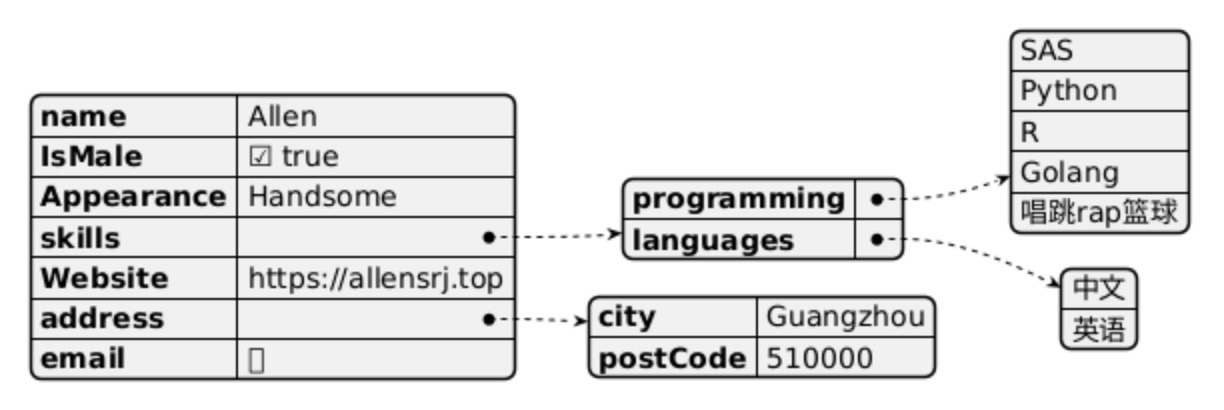
{
"name" : "Allen",
"IsMale" : true,
"Appearance" : "Handsome",
"skills": {
"programming": ["SAS", "Python", "R", "Golang", "唱跳rap篮球"],
"languages": ["中文", "英语"]
},
"Website" : "https://allensrj.top",
"address": {
"city": "Guangzhou",
"postCode": "510000"
},
"email": null
}用图片展示这个:
特点
轻量,比XML更小、更快、更易解析;
能够在众多编程语言中解析和使用;
方便阅读理解,具有自我描述性;
由于脱胎于JS,因此JavaScript可以使用内建eval()函数直接将JSON转换成原生对象。
应用场景
Web API:作为客户端和服务端的交换数据格式;
配置文件:以JSON格式作为配置文件;
数据库存储:如MongoDB等数据库技术采取JSON作为文档存储数据;
前端开发:在JavaScript中可以直接使用JSON作为对象。
局限
JSON虽然和JS对象关系密切,但只是数据格式,不是编程语法,无法添加注释;
数据类型有限,不直接支持日期时间类型,通常用ISO8601字符串表示
"2025-12-22T22:00:00Z";数值这一类型没有区分整数、浮点数、长整型等属性,因此不同编程语言在解析JSON时会按自身的方式处理数字,比如长达15位的整数会被解析错误、浮点数的小数部分存在一定的精度限制等;
不支持循环引用,JSON的属性结构不能表示为a.b=a这样的自引用对象。
如需要避免数值的问题,可以将长整数、高精度数值一律用字符串进行表示。
实例
通过实例认识一下JSON数据。在我们调用百度地图的API搜索:浦东/学校/初中,会得到结果如下的JSON内容,结果太长了只节选一部分,可以看到其中results就是我们获取的结果,包括了4所学校以及附属的具体信息,其他诸如status, message等指的是本次调用API的状态等“根”信息,层级高于结果。
{
"status": 0,
"message": "ok",
"result_type": "poi_type",
"query_type": "general",
"results": [
{
"name": "上海市进才实验中学",
"location": {
"lat": 31.231913849218206,
"lng": 121.56321997728149
},
"address": "上海市浦东新区金松路191号",
"province": "上海市",
"city": "上海市",
"area": "浦东新区",
"town": "花木街道",
"town_code": 310115016,
"street_id": "",
"telephone": "(021)68545988",
"detail": 1,
"uid": "37d3ab83dd9b3e92dbd89154"
},
{
"name": "上海市洋泾·菊园实验学校",
"location": {
"lat": 31.23386253041462,
"lng": 121.51794025923719
},
"address": "上海市浦东新区启新路1号(近浦城路)",
"province": "上海市",
"city": "上海市",
"area": "浦东新区",
"town": "陆家嘴街道",
"town_code": 310115005,
"street_id": "34ad08340335b6e65d17c30f",
"telephone": "(021)58781347,(021)58781633",
"detail": 1,
"uid": "34ad08340335b6e65d17c30f"
},
{
"name": "上海浦东新区民办恒洋外国语学校",
"location": {
"lat": 31.224261000031316,
"lng": 121.52885565931949
},
"address": "上海市浦东新区潍坊新村街道南泉路517号",
"province": "上海市",
"city": "上海市",
"area": "浦东新区",
"town": "潍坊新村街道",
"town_code": 310115004,
"detail": 1,
"uid": "9212821f5be489fe9ee32119"
},
{
"name": "上海张江集团中学",
"location": {
"lat": 31.207948406917513,
"lng": 121.60035422028352
},
"address": "上海市浦东新区藿香路38弄",
"province": "上海市",
"city": "上海市",
"area": "浦东新区",
"town": "张江镇",
"town_code": 310115125,
"street_id": "",
"telephone": "(021)50278818",
"detail": 1,
"uid": "d24e48eb49168cb5afee7a51"
}
]
}CDISC中的JSON格式数据集
PharmaSUG中这篇文章***\*PharmaSUG-2022-AD-150_ppt\****介绍了Dataset-JSON的来龙去脉,本文不再赘述。Dataset-JSON v1.1是CDISC在2024年12月推出的相关标准,在官网查看可以发现其中包括了Specifications,Examples和User's Guide,分别讲述了JSON格式的SDTM数据集说明、JSON格式数据集示例以及一些需要注意的细节。
Example里的json数据确实要比xpt体积小不少。

JSON格式的SDTM.DM示例理解
先贴一个完整的数据集示例:
{
"datasetJSONCreationDateTime": "2023-06-28T15:38:43",
"datasetJSONVersion": "1.1.0",
"fileOID": "www.sponsor.xyz.org.project123.final",
"dbLastModifiedDateTime": "2023-05-31T00:00:00",
"originator": "Sponsor XYZ",
"sourceSystem": {
"name": "Software ABC",
"version": "1.0.0"
},
"studyOID": "cdisc.com.CDISCPILOT01",
"metaDataVersionOID": "MDV.MSGv2.0.SDTMIG.3.3.SDTM.1.7",
"metaDataRef": "https://metadata.location.org/CDISCPILOT01/define.xml",
"itemGroupOID": "IG.DM",
"records": 18,
"name": "DM",
"label": "Demographics",
"columns": [
{"itemOID": "IT.DM.STUDYID", "name": "STUDYID", "label": "Study Identifier", "dataType": "string", "length": 12, "keySequence": 1},
{"itemOID": "IT.DM.DOMAIN", "name": "DOMAIN", "label": "Domain Abbreviation", "dataType": "string", "length": 2},
{"itemOID": "IT.DM.USUBJID", "name": "USUBJID", "label": "Unique Subject Identifier", "dataType": "string", "length": 8, "keySequence": 2},
...
{"itemOID": "IT.DM.AGE", "name": "AGE", "label": "Age", "dataType": "integer"},
{"itemOID": "IT.DM.AGEU", "name": "AGEU", "label": "Age Units", "dataType": "string", "length": 5},
...
],
"rows": [
["CDISCPILOT01", "DM", "CDISC001", ..., 84, "YEARS", ...],
["CDISCPILOT01", "DM", "CDISC002", ..., 76, "YEARS", ...],
["CDISCPILOT01", "DM", "CDISC003", ..., 61, "YEARS", ...],
...
]
}可以看出来,在"records", "name", "label"描述了SDTM.DM这个数据集的属性,之前的键值对分别描述了一些项目顶层信息的属性,而"columns", "rows"这两部分开始描述了数据集本身的内容。
"columns"内部每一个对象都是数据集的列信息,包含键值对中的键:必需itemOID, name, label, dataType,可选targetDataType, length, displayFormat, keySequence。
"rows"内部的每一个数组,其实就是数据集中的一整行数据。案例中的整数和浮点数都是直接放置的数值(如lborres和lborresn可以是"1.8618",1.8618),数值为空则显示为null,字符串类型的空值就是"",日期则显示为ISO 8601的字符串格式,某些小数为了表示终止小数分数而无需四舍五入可采用字符串表示(如"30.8983333232059")。
NDJSON格式
除了JSON数据格式之外,官方示例中还提供了NDJSON格式(即换行分隔的JSON),目的是简化大型数据集流式传输,可以一次读取或写入一行数据,节省运行内存。JSON和NDJSON的数据内容是一样的。
{"datasetJSONCreationDateTime": "2023-06-28T15:38:43", "datasetJSONVersion": "1.1.0", "fileOID": "www.sponsor.xyz.org.project123.final", "dbLastModifiedDateTime": "2023-05-31T00:00:00", "originator": "Sponsor XYZ", "sourceSystem": {"name": "Software ABC", "version": "1.0.0"}, "studyOID": "cdisc.com.CDISCPILOT01", "metaDataVersionOID": "MDV.MSGv2.0.SDTMIG.3.3.SDTM.1.7", "metaDataRef": "https://metadata.location.org/CDISCPILOT01/define.xml", "itemGroupOID": "IG.DM", "records": 18, "name": "DM", "label": "Demographics", "columns": [{"itemOID": "IT.DM.STUDYID", "name": "STUDYID", "label": "Study Identifier", "dataType": "string", "length": 12, "keySequence": 1}, {"itemOID": "IT.DM.DOMAIN", "name": "DOMAIN", "label": "Domain Abbreviation", "dataType": "string", "length": 2}, {"itemOID": "IT.DM.USUBJID", "name": "USUBJID", "label": "Unique Subject Identifier", "dataType": "string", "length": 8, "keySequence": 2}, ..., {"itemOID": "IT.DM.AGE", "name": "AGE", "label": "Age", "dataType": "integer"}, {"itemOID": "IT.DM.AGEU", "name": "AGEU", "label": "Age Units", "dataType": "string", "length": 5}, ...]}
["CDISCPILOT01", "DM", "CDISC001", ..., 84, "YEARS", ...]
["CDISCPILOT01", "DM", "CDISC002", ..., 76, "YEARS", ...]
["CDISCPILOT01", "DM", "CDISC003", ..., 61, "YEARS", ...]
...JSON在编程语言中的读取和输出
可以看出来,JSON数据在维度上更丰富了,比起之前的xpt数据集,变量层面多了keySequence变量,而数据集层面也多了一些项目顶层信息的属性。
如果是生产环境里,从SAS数据集输出到JSON肯定还是需要用到mddt spec等其他文件赋予JSON数据集属性,但是先从读取和输出做起,可以先聚焦在JSON数据集的"columns","rows"两个属性上,足以完成数据的读取和输出。
SAS读取和输出JSON格式SDTM数据集
SAS读取示例里dm.json,会在lib中产生5个数据集:alldata, columns, root, rows, sourcesystem,思路是用columns和rows把数据集读进SAS,rows读数据集、用columns给数据集的变量赋属性。
输出时用的是proc json导出数据集,用object建立对象,用array建立数组。
proc delete data=work._all_;run;quit;
/* ----- Read JSON */
/* 1. import json data */
filename mydata './dm.json';
libname my json fileref=mydata;
proc datasets lib=my nolist nodetails;
contents data=_all_;
quit;
/* 2. assign variable and label for rows json data */
data work.columns;
length col_var col_label $200.;
set my.columns;
col_var = cats(name, "=element", strip(put(ordinal_columns,best.)));
col_label = cats(name,"=","'",label,"'");
run;
proc sql noprint;
/* assign and label */
select col_var into: col_var separated by ";" from columns;
select col_label into: col_label separated by " " from columns;
/* other macro var */
select name into: keep_var separated by " " from columns;
select name into: var_str separated by " " from columns where datatype="string";
select name into: var_dt separated by " " from columns where datatype="date";
select name into: var_int separated by " " from columns where datatype="integer";
quit;
/* 3. output sdtm dataset */
data work.dm;
retain &keep_var;
length &var_str $200. &var_dt $20. &var_int 8.;
label &col_label;
set my.rows;
&col_var;
keep &keep_var;
run;
/* ----- Output JSON */
/* 1. extract attrib into metadata, should have originally come from mddt spec. */
proc sql noprint;
create table column_metadata as
select
cats('IT.DM.', strip(name)) as itemOID,
name,
label,
case when type = 'char' then 'string'
when type = 'num' then
case when format in ('DATE', 'YYMMDD10.', 'MMDDYY10.', 'DDMMYY10.', 'DATETIME', 'IS8601DT', ) then 'datetime'
else 'integer'
end
else 'unknown'
end as dataType,
case when type = 'char' then length else . end as length,
case when name in ('STUDYID', 'USUBJID') then
case when name = 'STUDYID' then 1 when name = 'USUBJID' then 2 end else .
end as keySequence
from dictionary.columns
where libname = 'WORK' and memname = 'DM'
order by varnum;
quit;
/* 2. Output JSON by proc json */
proc json out="a-test.json" pretty nosastags;
write open object;
/* input columns */
write values "columns";
write open array;
export work.column_metadata;
write close;
/* input rows */
write values "rows";
write open array;
export work.dm / nokeys nosastags;
write close;
write close;
run;R读取和输出JSON格式SDTM数据集
用$向树形结构里不断取值,除了下面的做法,R里面还有datasetjson包可以直接导出符合CDISC要求的数据集。
rm(list=ls())
library(pacman)
p_load(jsonlite)
# ----- Read JSON
data <- fromJSON('./dm.json')
col_names <- data$columns$name
colnames(data$rows) <- col_names
dm <- data$rows
# ----- Output JSON
# 1. set cols and row_list
cols <- data$columns
row_list <- lapply(seq_len(nrow(dm)), function(i) {
unname(as.list(dm[i, ]))
})
# 2. Combine and transfer to JSON
output <- list(columns = cols, rows = row_list)
json_str <- toJSON(
output,
auto_unbox = TRUE,
pretty = TRUE,
na = "null"
)
write(json_str, file = "dm.json")Python读取和输出JSON格式SDTM数据集
通过['']和[0],不断向树形结构内取值
import json
import pandas as pd
# ----- Read JSON
with open(“./dm.json", 'r') as f:
js = json.load(f)
col_name = [col['name'] for col in js['columns']]
dm = pd.DataFrame(js['rows'], columns=col_name)
# ----- Output dm to JSON
rows = dm.to_numpy().tolist()
dm_json = {
'columns' : js['columns'],
'rows' : rows
}
with open("dm_json.json", 'w', encoding='utf-8') as f:
json.dump(dm_json, f, ensure_ascii=False, indent=4)User Guide中的一些细节
JSON数据格式默认为
utf-8编码且支持Unicode;JSON格式的数据用
\转义;\"转义双引号,\\转义反斜杠,\/转义斜杠;特殊字符可以用\uXXXX作为转义序列。整数和浮点数在JSON中显示为数值型,但是Dataset-JSON团队添加了
decimal格式给dataType和targetDataType这两个属性,从原生数据集读取的decimal会转换成字符的形式。JSON中用符合ISO 8601的字符串表示日期,不用数值的原因是SAS以1960年1月1日0点作为纪元,而Unix编程语言如R、Python以1970年1月1日0点作为纪元,以数值显示两者会造成10年偏差。
API v1.0 Standard
在推出Dataset-JSON v1.1的同时,CDISC官网还推出了 API v1.0 Standard。既往我对API的理解通常是从用户的角度出发,比如百度地图的API接口,通过我自己的userid,只能通过程序取到运营商规定的内容。但是如果从API运营的角度出发,似乎能够理解CDISC在JSON格式上的宏伟蓝图。
API v1.0是一个行业技术协议规范,它规范了CDISC传输中数据长的样子,同时数据平台由各家药企、公司自行托管,那么就意味着:
各方相互交互数据的时候需要遵循API v1.0 Standard:
公司之间相互交付数据的时候,可以通过这套API标准交互;
药企给监管机构递交数据的时候,也可以用API进行递交(也许?);
药企在递交前,可以用这套API内容查漏补缺;
目前已用SAS生产的临床试验项目,如有必要在xpt和json格式间相互转换,依据也是它。
而JSON作为web数据传输的主流标准,能够获得诸多好处:
更轻量、数据维度更多、不再受既往xpt在字符长度和数据集体积大小以及字符集等方面的限制;
更加机器可读,方便后续多种编程语言开发、AI提效以及可视化平台接入;
大概看了下API v1.0 Standard,根据AI说是RESTful API接口规范,这个名词我仅限于听过没试过,或许百度API接口、akshare包这种都属于RESTful API接口吧。
目前为止大多数公司应该还是用xpt + Define-XML的方式递交,其实即使是xpt换成JSON,理论上也不是所有角色需要用到API v1.0 Standard,如果公司间还是手工相互交付数据的话,即使是转JSON格式,也只需要遵循Dataset-JSON v1.1的标准就好了,可能验证的时候需要熟悉一下API标准的内容查漏补缺(?我猜)。
必须要用到这个API标准的情况大概是:构建自动化的数据传输平台、数据接入可视化平台这种需要标准数据交互的场景。
参考内容
https://www.runoob.com/json/json-tutorial.html
https://www.cdisc.org/standards/data-exchange/dataset-json/dataset-json-v1-1
https://wiki.cdisc.org/display/PUB/Dataset-JSON+v1.1+User%27s+Guide
https://pharmasug.org/proceedings/2022/AD/PharmaSUG-2022-AD-150.pdf
https://pharmasug.org/proceedings/2025/DS/PharmaSUG-2025-DS-336.pdf
How to read JSON data in SAS - SAS Support Communities
SAS Help Center: Writing Values and Exporting Data in the Same Program
